

本日は、データセンターなどでの仮想化環境の運用について、私どものAPM(アプリケーションパフォーマンス管理)を活用した新しい手法を提案させて頂きたいと考えております。
ITシステムの運用を手掛けていらっしゃる皆様にとって物理サーバを複数の仮想化マシンに分割することでリソースを有効活用する仮想化は、避けて通れないテーマになっています。
仮想化には、サーバの増設が非常に容易であり、リソースの割り当てが柔軟に行える、運用の自動化も可能といった特徴があり、これらが設備コストの低減につながっています。
他方、設備の具体的な状況が把握しにくい「ブラックボックス化」やシステム構成が複雑になるなどの問題も指摘されています。運用担当者から見ると、ハードウェアを変更していないのに突然パフォーマンスが低下する、逆に何もしないのに自動的に復旧するなどの状況が頻繁に生じているわけです。これと構成の複雑さとが相まって、従来の障害対応の手法がとりにくくなっています。実はこれが大きな問題なのではないかと思います。
私どものあるお客様では、社内システムの仮想化を計画し、第1弾として3台の物理サーバそれぞれに10台の仮想マシンを乗せて運用を始められました。将来的には数100台の物理サーバが仮想化の対象になります。
実際にこの環境で運用を開始したところ、エンドユーザに影響が出てシステム担当者が復旧に動かなければならない程に重要な障害の発生件数は、従来とほぼ同じでした。
他方で、(1)MTTR(障害が復旧するまでの時間)が長くなる、(2)エンドユーザからのクレーム件数の増加、(3)管理システムからのアラートの数が倍になるなどの問題も生じています。仮想化により、システム担当者の負担が非常に重くなっているわけです。
こうした状況に対し、監視システムのベンダーからは、リソースの利用状況などについてより詳細なデータをとれるようにする、仮想化と監視システムのコンソールを一元化するなどの提案が行われました。
もちろんこれ自体は否定されるものではありません。しかし、私どもは1台1台のサーバの管理を強化しても問題の抜本的な解決にはつながらないと考え、弊社のAPMの導入と運用への移行を提案させて頂きました。
APMにはいくつかの種類があるのですが、提案させて頂いたものは、仮想スイッチからパケットをキャプチャするタイプ。このパケットの内容を分析することで、システムのレスポンスタイムなど、各ユーザのリアルな体感を把握することができます。
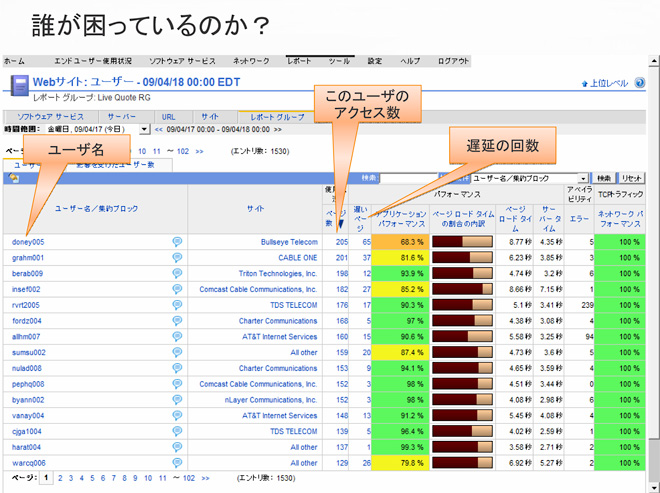
運用面では、APMでユーザに実際に影響が出ていることが把握できた障害についてのみ復旧対応を行い、それ以外は優先順位を下げるという提案をさせて頂きました。監視システムからアラートが上がってもユーザに影響がなければ対応を後回しにして、例えば1週間に1度まとめて対応しようというわけです。
仮想化環境では、仮にあるサーバのCPU負荷が過剰になっても、システムが自動的にこれを分散するといった対応が行われ、多くの場合ユーザには影響は出ません。にもかかわらず多くの企業は、仮想化環境下でも従来通り監視システムのアラートを受けて、すべてのサーバを正常な状態に保とうと努力しています。これが大きな負担になっているのです。それでいて肝腎のユーザの使用感が低下していても気づきにくい、という皮肉な状況も生まれています。APMの導入と運用変更で、これらを解消できるのです。
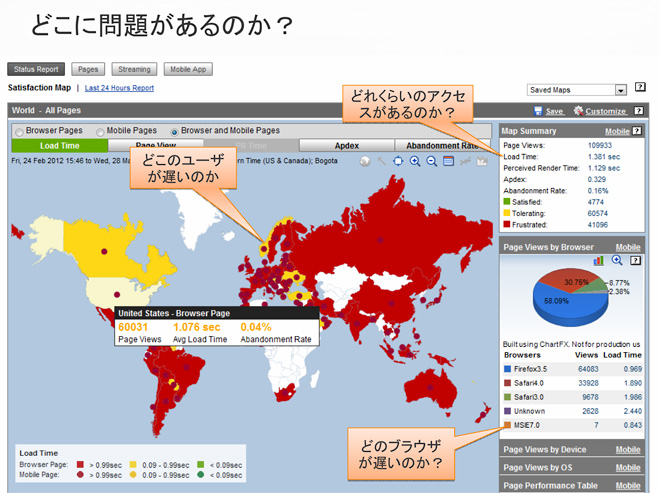
海外のデータセンターでは2万台の物理サーバをわずか2名で運用するケースも出てきています。これを可能にしているのが、監視・運用の発想の転換なのです。1万台の物理サーバのうち100台くらいダウンしてもユーザには影響がないと割りきっているのです。同様の手だてをとることで、日本のお客様も仮想化の本来のメリットを享受することができるようになるはずです。私どものAPMソリューションがその助けになればと願っております。
(文責・編集部)
